一、说明介绍与机场推荐
全球节点更新啦!涵盖美国、新加坡、加拿大、香港、欧洲、日本、韩国等地,提供10个全新订阅链接,轻松接入V2Ray/Clash/小火箭等科学上网工具,简单复制、粘贴即畅享全球网络自由!只需复制以下节点数据,导入或粘贴至v2ray/iso小火箭/winxray、2rayNG、BifrostV、Clash、Kitsunebi、V2rayN、V2rayW、Clash、V2rayS、Mellow、Qv2ray等科学上网工具,即可直接使用!
二,自用机场推荐
包月(不限时)最低5元起150GB流量:点我了解详情
同步电报群:https://t.me/xfxssr
永久发布页地址,防丢失https://sulinkcloud.github.io/
三,节点列表和测试速度










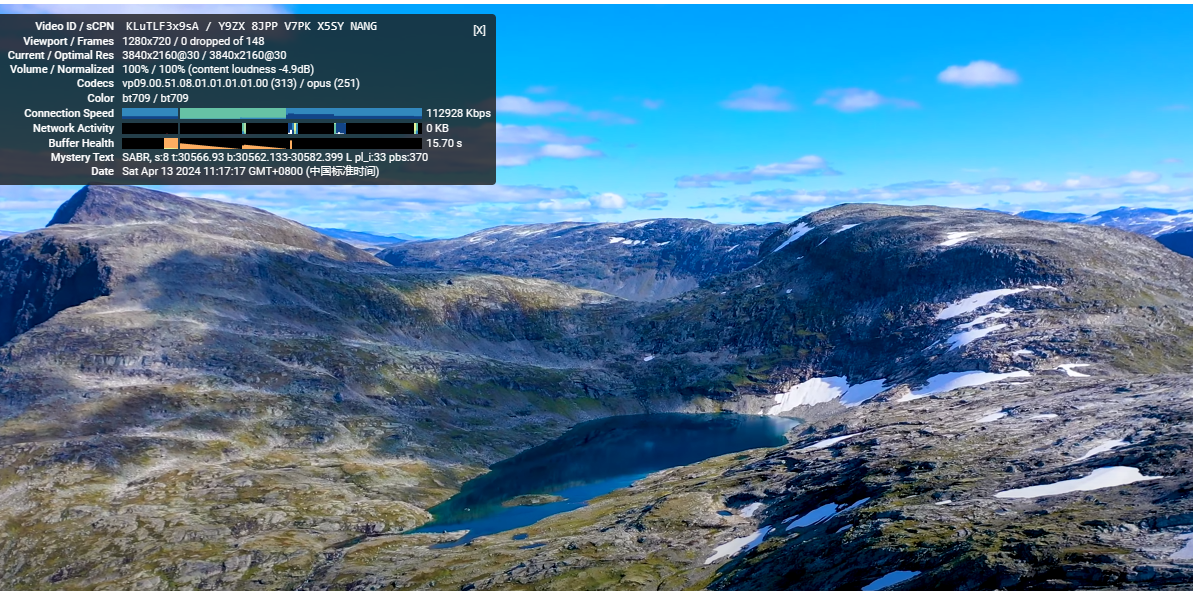
clash verge 测试速度超快,看油管4k无压力
200个免费节点分享

分割线
如何用 Python 分析 Excel 数据并生成可视化图表?
解答步骤:
安装库:
bash
pip install pandas openpyxl matplotlib seaborn
读取 Excel 数据:
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取文件
df = pd.read_excel(‘data.xlsx’, sheet_name=’Sheet1′)
# 查看数据概况
print(df.head())
print(df.info())
数据清洗(示例):
python
# 处理缺失值
df = df.fillna(0) # 用0填充缺失值
# 筛选数据
filtered_df = df[df[‘销售额’] > 1000]
数据分析:
python
# 分组统计
group_data = df.groupby(‘地区’)[‘销售额’].sum()
print(group_data)
# 相关系数分析
corr = df[[‘销售额’, ‘广告投入’, ‘客户数量’]].corr()
print(corr)
生成可视化图表:
python
# 柱状图:各地区销售额对比
plt.figure(figsize=(10, 6))
sns.barplot(x=group_data.index, y=group_data.values)
plt.title(‘各地区销售额分布’)
plt.xticks(rotation=45)
plt.tight_layout()
# 折线图:销售额随时间变化
time_series = df.groupby(‘日期’)[‘销售额’].sum()
plt.figure(figsize=(12, 5))
plt.plot(time_series.index, time_series.values)
plt.title(‘销售额时间趋势’)
plt.grid(True)
# 热力图:相关系数可视化
plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, cmap=’coolwarm’)
plt.title(‘数据相关性热力图’)
plt.show()
保存结果:
python
# 保存分析后的数据
filtered_df.to_excel(‘filtered_data.xlsx’, index=False)
评论